Users should not be systemically disadvantaged by the language they use for interacting with LLMs; i.e. users across languages should get responses of similar quality irrespective of language used. In this work, we create a set of real-world open-ended questions based on our analysis of the WildChat dataset and use it to evaluate whether responses vary by language, specifically, whether answer quality depends on the language used to query the model. We also investigate how language and culture are entangled in LLMs such that choice of language changes the cultural information and context used in the response by using LLM-as-a-Judge to identify the cultural context present in responses. To further investigate this, we evaluate LLMs on a translated subset of the CulturalBench benchmark across multiple languages. Our evaluations reveal that LLMs consistently provide lower quality answers to open-ended questions in low resource languages. We find that language significantly impacts the cultural context used by the model. This difference in context impacts the quality of the downstream answer.

We created a set of 20 advice-seeking questions covering a wide variety of topics like Healthcare, Business, and Education for evaluating performance on open-ended tasks. These questions were created based on our analysis of the WildChat Dataset.
As part of our analysis, we began with initial filtering and cleaning. From the WildChat dataset, we retained only queries in English and removed queries related to programming bugs or error fixes, as they are niche and skew the dataset. We kept queries with lengths ranging from 40 to 400 characters and excluded duplicate or highly similar queries with a threshold of 60 using the fuzzywuzzy library.
We converted the queries to embeddings using the Qwen3-0.6b embedding model and clustered them using the HDBSCAN algorithm, followed by manual analysis to create the evaluation queries. The questions were structured in a culture-independent manner. We then translated the queries to Chinese, Hindi, Brazilian Portuguese, Swahili, and Hebrew using the Gemini-2.5-Flash model.
| Category | Queries |
|---|---|
| Programming Advice |
|
| Research Advice |
|
| Trading/Investing |
|
| Learning |
|
| Business/Marketing |
|
| Job/Interview |
|
| Health/Medicine |
|
We also translated a subset of the CulturalBench dataset to Hindi, Chinese, Brazilian Portuguese, Swahili, and Hebrew to further investigate cultural entanglement. The following graph presents the performance of Qwen3-14b on the Multilingual CulturalBench by language and country of origin.
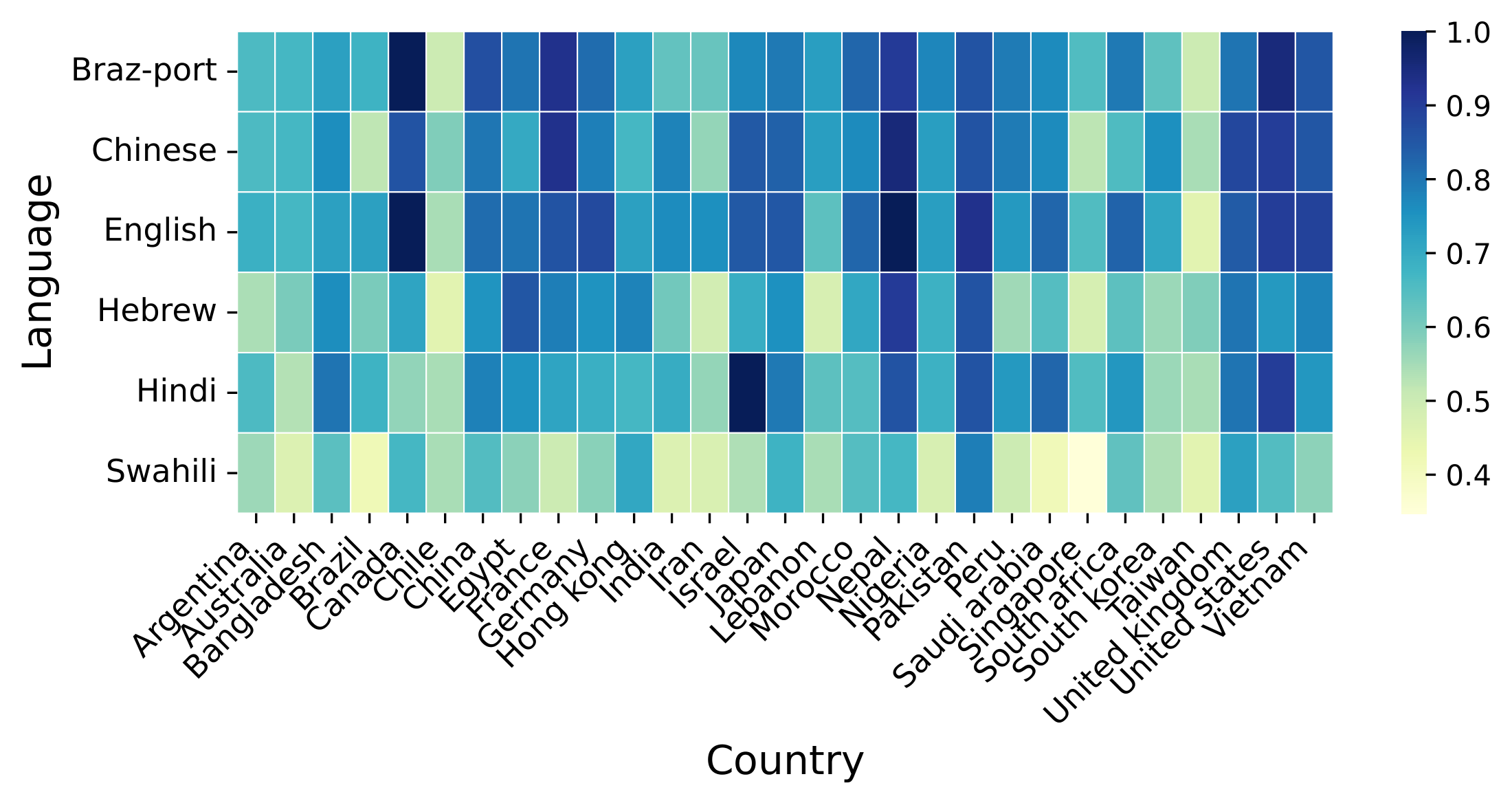
Qwen3-14b performance on the Multilingual CulturalBench by language and country of origin.
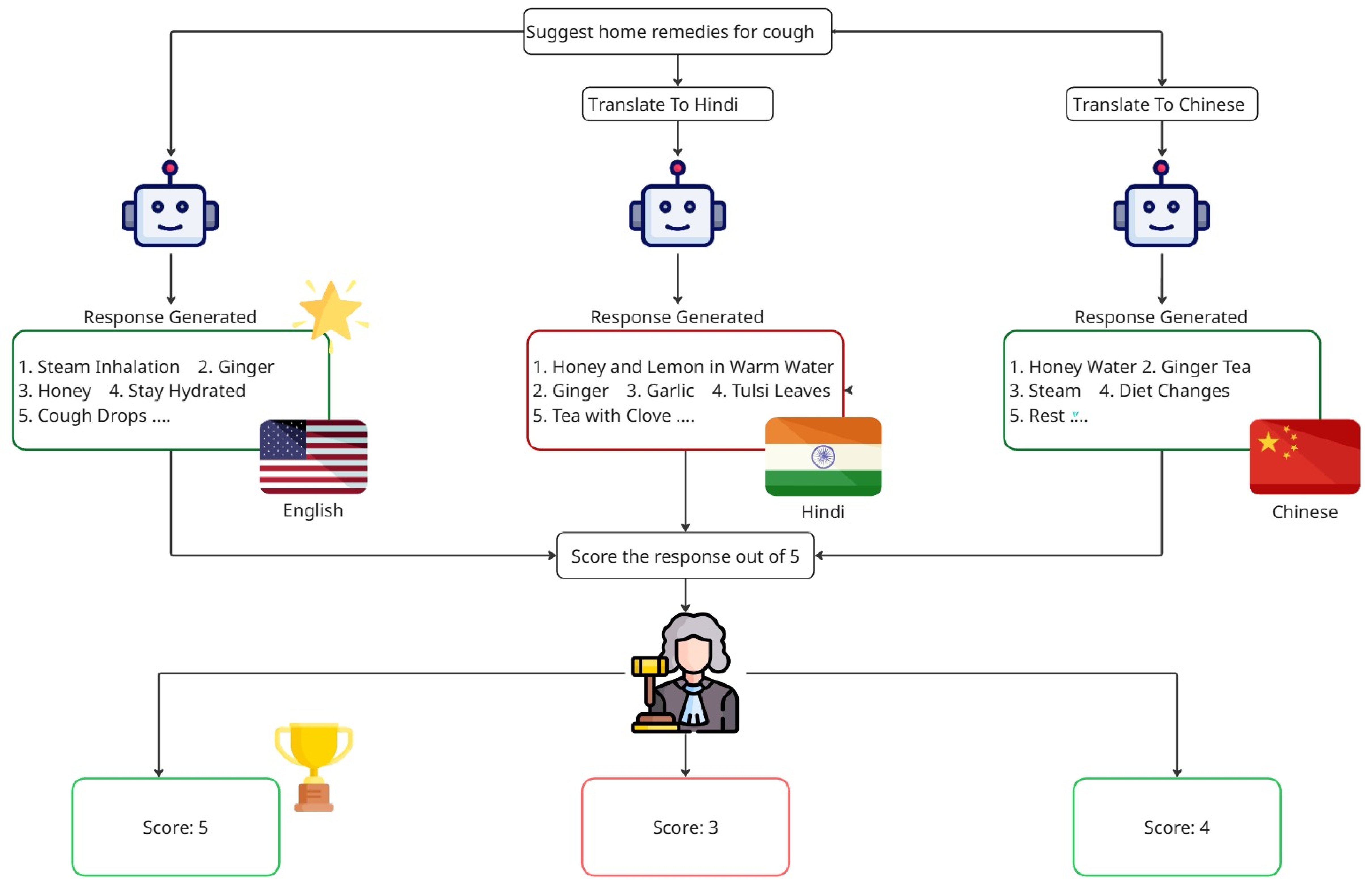
Overview of Evaluation Methodology
For each question and language pair, we generate 10 responses per model with temperature set to 1. We evaluate all the responses using LLM as a Judge with the temperature set to 0. Our evaluation covered the following models: Qwen3-14B, Cohere-Aya-32B, Cohere-Aya-8B, Magistral and Sarvam-m.
To ensure the quality of evaluation using LLM-as-a-Judge, we performed several ablations to choose the best configuration. We took a subset of 10 queries from the 20 queries we created and a subset of languages: English, Hindi, Chinese and Hebrew. For each query and language pair, we prompted Cohere-Aya-32B to generate 5 responses, corresponding to scores from 1 to 5 by providing it the rubrics to be used for evaluation. We use these responses for evaluating our Judge and the score corresponding the response as the ground truth score.
We use Cohere Command-A model and test 6 configurations of LLM-as-a-Judge:
(i) Original query along with original response (Baseline)
(ii) Original query along with response translated to English
(iii) Query translated to English along with original response
(iv) Original query and original response along with 2 reference responses as examples
(v) Original query and original response along with 4 reference responses as examples
(vi) Original query and original response along with 8 reference responses as examples
We note that we only provide randomly chosen reference responses to the model without any evaluation, making our methodology different from few-shot prompting and eliminating the need for human evaluated responses for reference. Providing reference examples to the model leads to higher alignment with ground truth scores as evaluated using Pearson correlation and Cohen's Kappa score. Using original query and response along with 8 randomly chosen examples lead to the highest alignment, hence we choose this configuration for our evaluations.
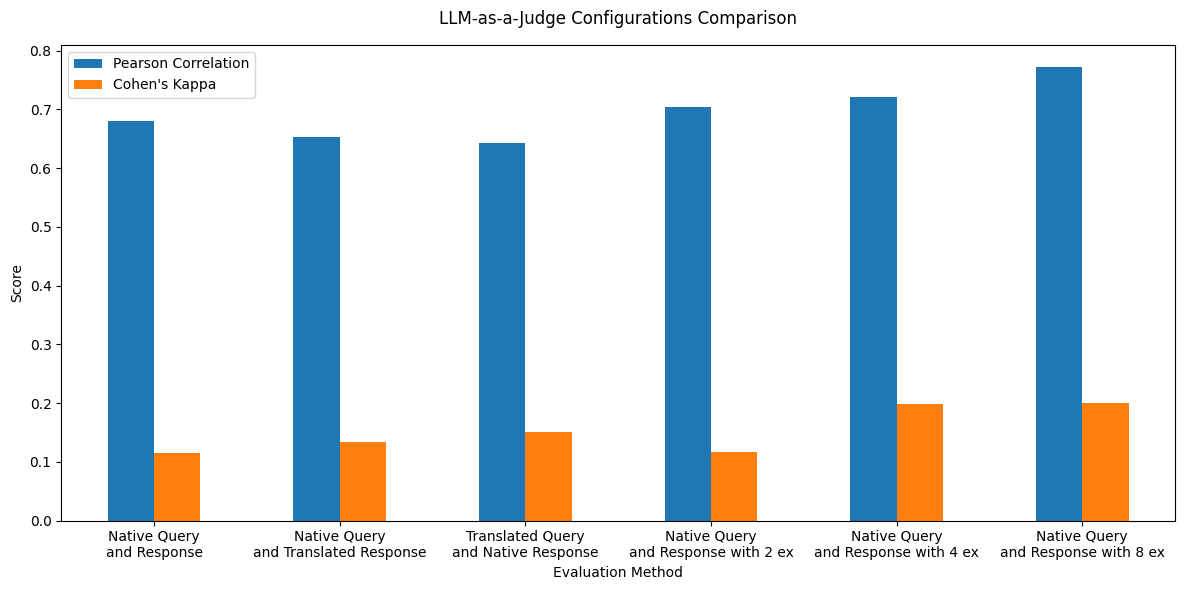
LLM-as-a-Judge Ablation Results
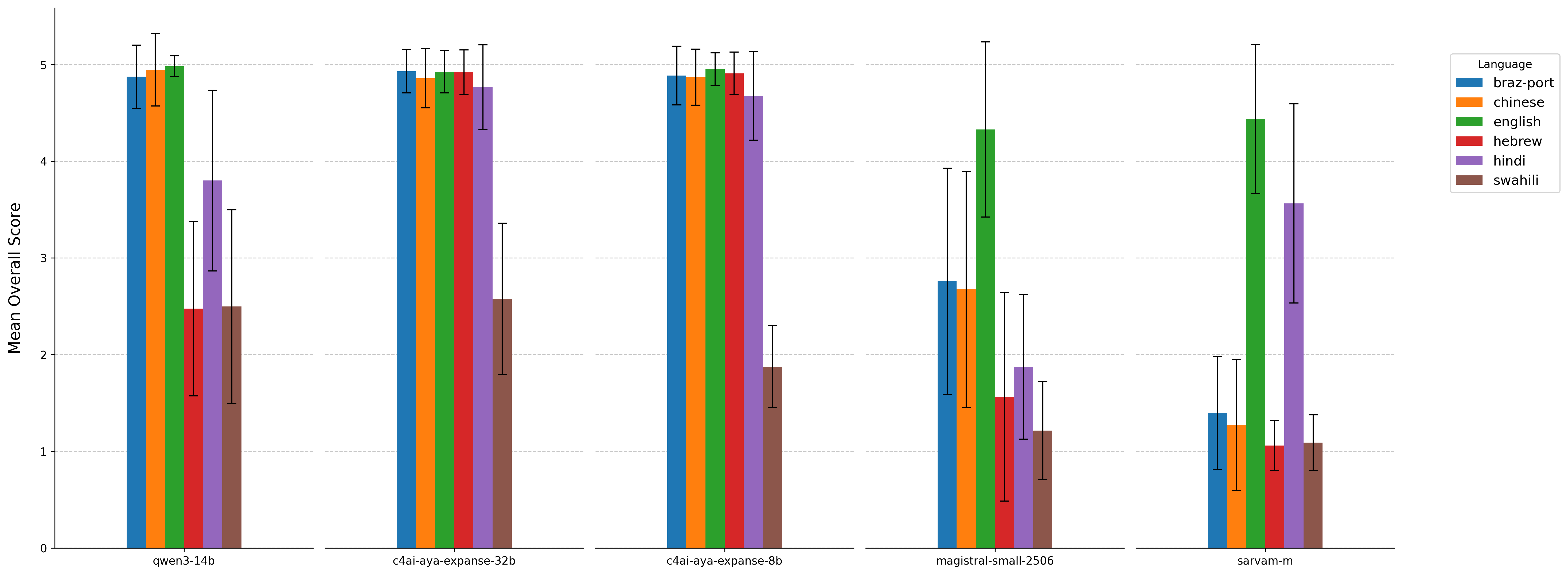
Comparison of Response Quality by Language and Model
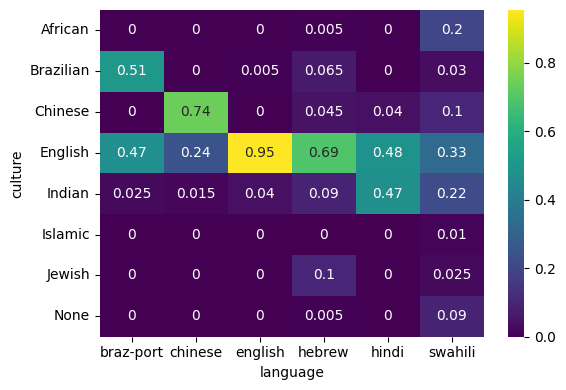
Percentage of responses classified to each culture by language
@misc{jain2026languagemodelsentanglelanguage,
title={Language Models Entangle Language and Culture},
author={Shourya Jain and Paras Chopra},
year={2026},
eprint={2601.15337},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2601.15337},
}